
Contributed post: Thank you to the team at Halo Radius for sharing their insights with the TechForward community!
Amazon Nova is a new class of large foundation models built for production-grade AI on AWS. It doesn’t run in a sandbox or behind APIs. Nova lives inside Amazon Bedrock, runs on custom AWS silicon, and slots directly into your existing cloud stack, secure, fast, and ready to ship.
Amazon Nova isn’t experimental; it’s operational. From model execution to access control, everything follows AWS principles: infrastructure you don’t manage, IAM roles you already use, and scaling you never worry about.
The Model Family Built for AWS Workloads
Amazon Nova is not one model; it’s a structured lineup:
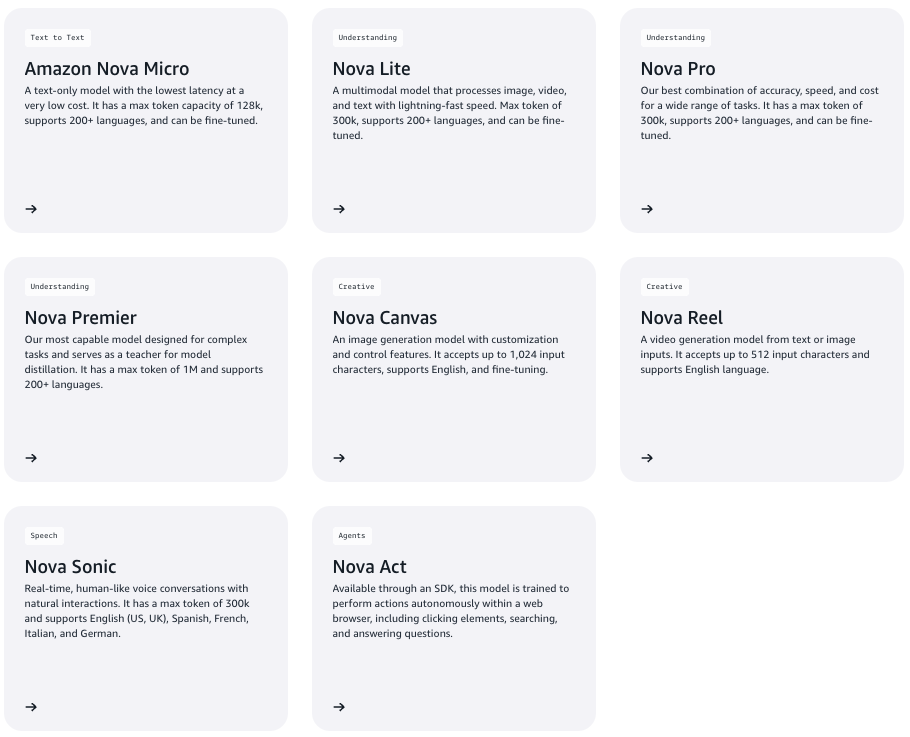
Each model offers a different balance of latency, capability, and cost. Whether you’re building chatbots or document analysis tools, there’s a variant tuned for your needs. All models run inside Amazon Bedrock, with native support for secure input handling, consistent logging, and enterprise billing.
You get full access through a standard Bedrock API call. No model hosting. No GPU provisioning. No weird third-party permissions.
No Infrastructure, Just Output for Amazon Nova
Calling a Nova model is as simple as any other AWS service. One SDK call. One permission model. One bill.
| # Set the model ID, e.g. Amazon Nova Lite, Pro. model_id = “amazon.nova-pro-v1:0” # Load the document with open(“example-data/amazon-nova-service-cards.pdf”, “rb”) as file: document_bytes = file.read() # Start a conversation with a user message and the document conversation = [ { “role”: “user”, “content”: [ {“text”: “Briefly compare the models described in this document”}, { “document”: { # Available formats: html, md, pdf, doc/docx, xls/xlsx, csv, and txt “format”: “pdf”, “name”: “Amazon Nova Service Cards”, “source”: {“bytes”: document_bytes}, } }, ], } ] try: # Send the message to the model, using a basic inference configuration. response = client.converse( modelId=model_id, messages=conversation, inferenceConfig={“maxTokens”: 500, “temperature”: 0.3}, ) # Extract and print the response text. response_text = response[“output”][“message”][“content”][0][“text”] print(response_text) except (ClientError, Exception) as e: print(f”ERROR: Can’t invoke ‘{model_id}’. Reason: {e}”) exit(1) |
You run your prompt. Bedrock runs the model. IAM keeps it secure. CloudTrail logs the call.
That’s the difference: Nova takes care of the tooling that often holds teams back from getting AI to production.
Multimodal Input, Single Call
Nova Pro and Premier support multimodal input. That includes text, image, and video in the same request. Inputs get encoded into a shared format, processed through a unified transformer, and decoded to output all in a single operation.
This design avoids stitched-together pipelines. You skip the complexity of managing multiple models or fusion logic. Use cases like timestamped summaries from product demo videos or visual inspection reports become straightforward.
Bigger Context, Less Glue Code
Nova Pro and Premier support input sizes up to 300,000 tokens. That’s enough for:
- 30 minutes of audio transcripts
- Entire legal contracts
- Multi-document research sets
You don’t need to chunk documents or orchestrate multiple calls. The model sees all relevant context at once, which improves answer quality and reduces coordination logic. This saves developer time and minimizes architectural sprawl.
For comparison, many commercial models still cap out at under 100K tokens, requiring more engineering effort for long-form input handling.
RAG-Ready and Distillable
Nova models support Retrieval-Augmented Generation (RAG) without retraining. You can enrich responses with real-time or private data from sources like internal documentation, vector stores, or event logs. That gives you domain-specific performance without model surgery.
For lower-latency applications, you can distill larger models (e.g., Nova Premier) into smaller variants like Micro or Lite. This gives you the logic and behavior of the larger model at a reduced cost and faster inference speed. For more on this approach, Hugging Face’s distillation guide explains it well.
This setup gives you the flexibility to scale across use cases, without switching providers or redesigning your system.
Why Amazon Nova Matters
Amazon Nova works where you already work. If your architecture runs on AWS Lambda, Step Functions, ECS, S3, and Nova slots natively. No additional monitoring agents. No cross-cloud security gaps. No data egress traps.
For developers, this removes blockers. You can go from proof of concept to production without swapping tools or rewriting access layers. And with native Bedrock support, you track cost, usage, and performance the same way you do with every other AWS service.
Final Take
Most developers don’t care about model families. They care about getting real work done without adding layers of risk or complexity. Amazon Nova delivers on that. You get LLMs that run inside your stack, speak your APIs, and don’t require new workflows or new vendors. It feels like infrastructure, not overhead.
You don’t have to chase benchmarks or reinvent pipelines. You just built. If you’ve ever struggled to wire an external model into AWS cleanly or watched a promising prototype stall in security review, Nova solves that problem for good.
Want to see how Amazon Nova fits into your stack? Let’s talk to Halo Radius about how it works under the hood.
Halo Radius is a consulting collective led by experienced Silicon Valley CTOs and engineering leaders. They help clients in Technology, Finance, and Logistics solve complex problems and accelerate growth. With expertise in Generative AI, LLMs, Machine Learning, Data Science, and cost-efficient software development, they build world-class SaaS and AI products. Their work combines technical precision with strategic clarity to deliver results that scale.

{kind=link}