
How usage data and inference costs drove Anthropic and OpenAI to build identical tier structures for AI coding agents.
Anthropic’s Claude Code and OpenAI’s Codex both open at roughly $20 per month for individuals. Serious developers who rely on them daily soon hit rate limits. The next step costs exactly $200 per month. This gap is no accident. It reflects hard data on user behavior, compute economics, and revenue optimization that both companies have now validated at scale.
The Tier Structure at a Glance
Both tools follow the same playbook. It’s not quite at the level of collusion, but there is little doubt that they feed off of each others’ market adoption and price anchoring:
| Tool | Entry Tier | Price | Best for | Power Tier | Price | Usage Multiple |
|---|---|---|---|---|---|---|
| Claude Code | Pro | $20/mo | Light-to-moderate coding | Max 20x | $200/mo | 20x |
| Codex | ChatGPT Plus | $20/mo | Occasional sessions | ChatGPT Pro | $200/mo | ~10x (priority + volume) |
Anthropic also offers a $100 “Max 5x” bridge tier. OpenAI skipped the middle step. The pattern is clear: low barrier for trial and acquisition, steep jump for sustained professional use.
Usage Data That Shaped the Model
AI coding agents are not chatbots. They run multi-step agentic workflows (reading codebases, editing files, running terminal commands, iterating on errors). A single heavy session can consume orders of magnitude more tokens than casual prompting.
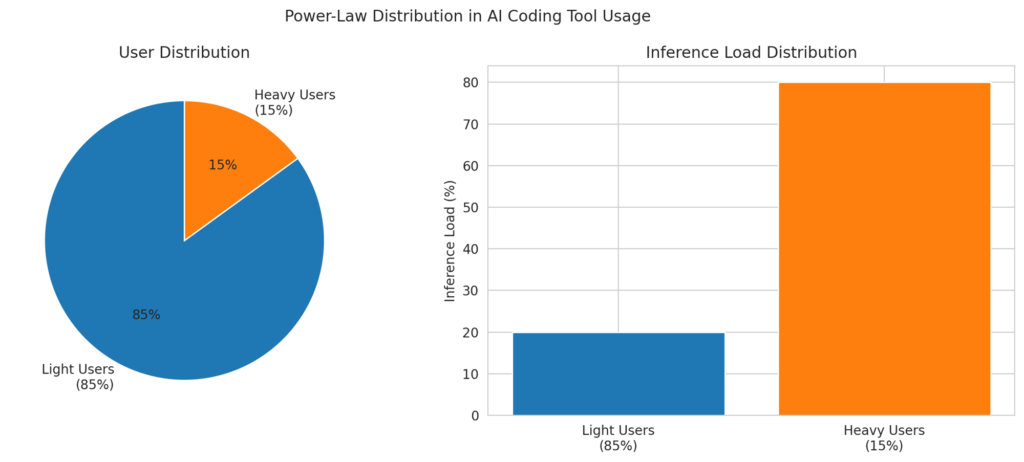
Internal telemetry (publicly discussed in earnings calls and product updates) shows classic power-law distribution: 80-90 % of users stay well under Pro limits, while the top 5-10 % generate the vast majority of inference load. Anthropic and OpenAI both learned this lesson the hard way with earlier flat-rate experiments. Light users subsidize heavy ones until you cap or tier aggressively. The $200 tier isolates the high-consumption cohort without forcing everyone else to pay for compute they never use.
Rate-limit resets (typically every 5 hours) further reinforce the price and feature segmentation. Developers notice when they bump the ceiling mid-project and upgrade rather than switch tools. It’s like Robux for adults.
Inference Costs and Margin Math
Frontier models cost real money to run. Opus-class reasoning plus tool-calling and code execution can equate to thousands of dollars per month in raw API pricing for the heaviest users. One analysis showed a $200 Claude Code Max subscription delivering usage that would cost $1,000+ on pay-as-you-go tokens.
The $200 flat fee gives vendors two wins:
- Predictable, high-margin revenue from committed power users.
- A natural hedge against variable inference spikes.
OpenAI reported a $300 million annualized revenue lift from its $200 Pro tier within months of launch. Anthropic introduced Max explicitly as a response to that data point.
Why Vendors Love the Structure, and Why Everyone Else Will Copy It
- Customer segmentation without complexity – $20 acquires broad adoption and data. $200 captures the users who extract the highest business value (and are willing to expense it).
- Cost control – Heavy users self-select into the tier that actually covers their compute. No more unlimited subsidies for agentic loops.
- Revenue predictability – Subscription revenue beats unpredictable token billing for planning GPU clusters and R&D budgets.
- Competitive lock-in – Once a developer’s workflow embeds Claude Code or Codex at the Pro or Max level, switching costs rise fast. The pricing moat keeps rivals from easily undercutting on features alone.
Cursor, Replit, and other AI IDEs already show signs of adopting similar stepped pricing. The model works because the underlying economics (massive fixed costs per heavy user and extreme usage variance) apply industry-wide.
What This Means for Builders and Teams
For solo developers or light users, the $20 tier remains as the easy on-ramp with genuine productivity gains. For full-time professional work, the $200 tier quickly pays for itself in hours saved (often in a single week). Teams can budget the jump as a line item once usage data proves ROI.
The pattern is set, and adoption metrics are proving out the approach. Expect more AI infrastructure tools to copy the $20 starter / $200 professional split. It is not marketing theater. It is the rational response to real usage curves and real inference bills. The vendors who master this math will fund the next wave of models. The rest will struggle to keep the lights on.

{kind=link}