
New quantization technique slashes LLM memory use and boosts inference speed on existing hardware.
Google Research released TurboQuant, a training-free quantization method that compresses key-value (KV) caches in large language models to as little as 3 bits per value.
The result: at least 6x lower memory footprint with no drop in accuracy on long-context tasks, plus up to 8x faster attention computation on H100 GPUs. Wow!
The approach targets one of the biggest practical headaches in LLM serving: KV cache bloat during inference. For models handling thousands of tokens, this cache can consume gigabytes and throttle throughput. TurboQuant fixes it without retraining or fine-tuning, making it immediately usable for production workloads.
I’ve been spending a lot of time in optimization, so this is something i was extremely happy to be able to nerd out on. Let’s walk through how it works and why it matters.
The Core Technique: PolarQuant + QJL
TurboQuant combines two mathematically grounded components. First, PolarQuant rotates input vectors randomly, then maps them into polar coordinates. Angles concentrate predictably after rotation, so they quantize cleanly with low-bit codebooks. There is no per-block scale or zero-point overhead that usually eats extra memory in standard methods. Radius and angles reconstruct the original vector with minimal error.

Figure 1. PolarQuant transformation mechanism.
Credit: Google Research blog
Second, Quantized Johnson-Lindenstrauss (QJL) adds a 1-bit residual correction. It applies a random projection and sign quantization to the quantization error from the first stage, then uses an unbiased estimator to recover accurate inner products for attention. The net effect keeps dot-product calculations faithful to full precision.
Together they form a two-stage pipeline (TurboQuant_mse for L2 error, TurboQuant_prod for inner-product fidelity) that operates online and data-obliviously. No codebooks tuned to your specific dataset. No offline preprocessing.
The math hits near theoretical lower bounds: distortion scales as roughly 1/4^b per bit width b, within a small constant factor of Shannon’s source-coding limits.
Real-World Numbers on LLMs and Vector Search
On Llama-3.1-8B-Instruct and Ministral-7B, TurboQuant at 2.5–3.5 bits matches or exceeds full-precision scores on LongBench while using 4–5× less KV memory. Needle-in-a-Haystack recall stays at 0.997 (identical to 16-bit) even at 104k context. It beats KIVI, SnapKV, and PyramidKV at equivalent bit widths.
For 4-bit operation on H100, attention logit computation runs up to 8× faster than the unquantized baseline. Vector-search indexing on GloVe and DBpedia datasets finishes in milliseconds instead of minutes or hours compared with product quantization baselines, while delivering higher recall.
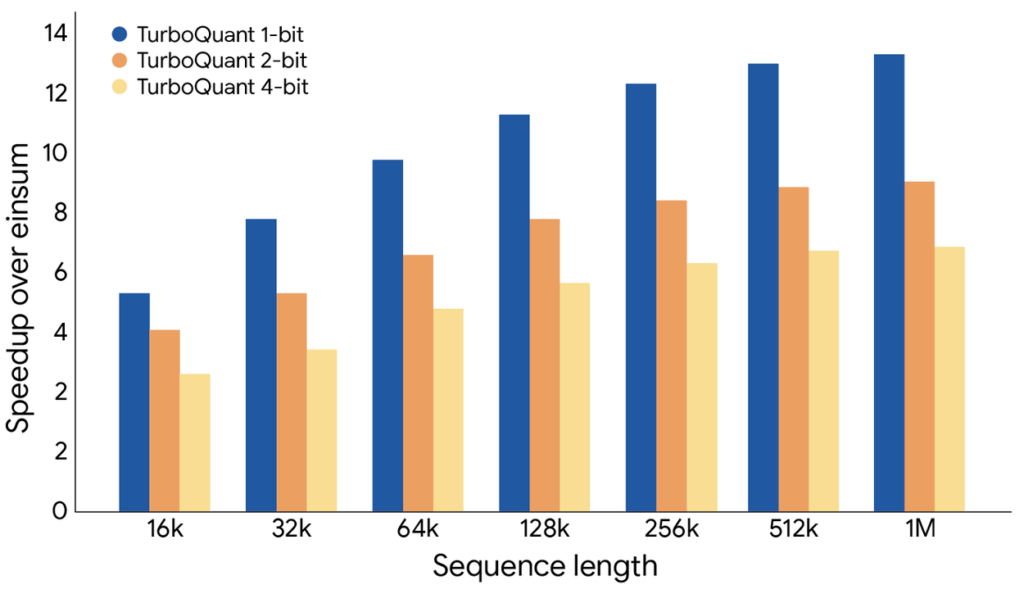
Figure 2. Attention logit computation speedup across bit widths on H100 GPUs (relative to unquantized baseline).
Credit: Google Research blog
Early Community Momentum
Developers moved fast. Within hours of the release, contributors added TurboQuant support to llama.cpp and published a PyTorch reference implementation. Interactive visualizations of the polar transformation already circulate on GitHub.
This speed of adoption signals real practitioner value: drop-in compatibility with existing inference stacks, CUDA kernels included, and zero accuracy tax.
Why It Matters Now
Inference costs still dominate LLM economics. Every token of context saved in memory translates directly to higher throughput or lower GPU bills. Edge and on-device scenarios (where 16-bit KV caches simply don’t fit) gain even more. TurboQuant lets teams run longer-context models on the same hardware or pack more concurrent users per accelerator.
It also strengthens vector databases and retrieval-augmented generation pipelines. Faster index builds and lower memory mean cheaper semantic search at scale.
The bigger picture is tighter alignment between algorithmic research and production constraints. Google proved you can push quantization to extreme bit widths while staying provably close to information-theoretic optima. No hand-waving heuristics required.
For platform engineers and inference teams, the message is clear: benchmark TurboQuant on your longest-context workloads today. The 6x memory win is real, the speedup is measurable, and the integration path is short. This is the kind of compression that moves from research blog to default setting in production stacks.
Data Source References
- Google Research Blog: “TurboQuant: Redefining AI efficiency with extreme compression” (March 24, 2026) — https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
- TurboQuant paper (arXiv:2504.19874) — https://arxiv.org/abs/2504.19874
- PolarQuant paper (arXiv:2502.02617) — https://arxiv.org/abs/2502.02617
- Quantized Johnson-Lindenstrauss paper (arXiv:2406.03482) — https://arxiv.org/abs/2406.03482

{kind=link}